
Long Horizon Tasks

为什么长任务容易失败
当 AI Agent 面对一个需要数小时甚至数十小时才能完成的复杂项目时,三个致命问题会反复出现:

- 意图漂移 — Agent 在执行过程中逐渐偏离原始目标。每一步看起来合理,但累积起来方向已经完全偏了。就像在沙漠中没有指南针,每次转弯都会让你离目标更远。
- 上下文丢失 — Session 中断后(context 满、超时、手动中止),新 session 无法恢复之前的决策背景。Agent 不记得做过什么决定、为什么做这些决定。
- 验证缺失 — 错误在早期引入,但一直到最后才被发现。累积的错误形成了难以拆解的依赖链,修复成本呈指数增长。
核心公式
Long Horizon Tasks 方法论提出一个简洁的成功率模型:

四个变量,四个 Markdown 文件,每个文件最大化一个变量:
| 变量 | 文件 | 作用 |
|---|---|---|
| 意图清晰度 | SPEC.md | 冻结目标,防漂移 |
| 分解粒度 | PLAN.md | 里程碑路径,可追踪 |
| 验证频率 | RULES.md | 行为约束,每步验证 |
| 状态可见度 | STATUS.md | 实时状态,可恢复 |
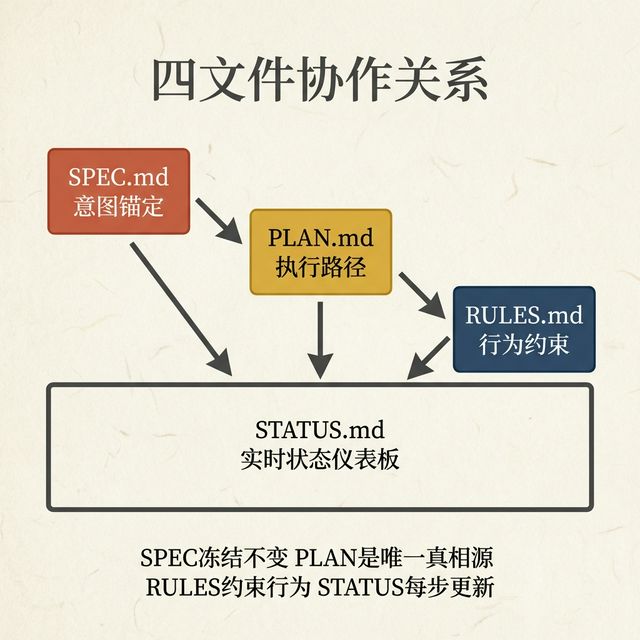
这四个文件构成一个闭环控制系统。它们不存在于 Agent 的 context 窗口中,而是持久化在项目目录里 — 不会因 session 中断而丢失。
四文件系统

文件一:SPEC.md — 意图锚定

SPEC.md 是项目的宪法。它冻结了项目的 What(做什么)和 Why(为什么做),一旦人工审核通过就不再修改。
它回答以下问题:
- 项目概述 — 一段话描述项目全貌
- 目标受众 — 谁会使用这个项目
- 核心目标 — 必须实现的功能
- 非目标 — 明确声明不做的事情
- 产品规格 — 按功能模块的详细规格
- 硬约束 — 技术栈、性能要求、兼容性
- 完成定义 — 如何判断项目已完成

文件二:PLAN.md — 执行路径

PLAN.md 是项目的唯一执行真相源(Single Source of Truth)。它将开放式的工作转化为可验证的检查点序列。
关键内容:
- 指导原则 — 全局性的技术决策方向
- 里程碑列表 — 每个含范围 / 关键文件 / 验收标准 / 验证命令
- 风险登记表 — 识别技术风险并安排早期验证
- 架构概述 — 核心模块关系图
- 决策日志 — 记录每个重要决策的理由和替代方案

里程碑设计四原则
- 单循环可完成 — 每个里程碑约 1 小时内完成
- 可独立验证 — 有明确的验收标准和验证命令
- 递进依赖 — 后续里程碑依赖前序里程碑的交付物
- 至少 14 个 — 粒度足够细才能有效控制(原始实验用了 24 个)

文件三:RULES.md — 行为约束

RULES.md 定义 Agent 的操作规范和行为边界。它不是建议,而是硬性约束。
核心规则包括:
- 不要停下来问 — 自主决策并记录到决策日志
- 小步提交 — 保持 diff 小且可审查
- 每步验证 — 每个里程碑后跑全套验证
- 错误即测试 — 出 bug 先写测试再修复
- 实时更新 — STATUS.md 必须在每步后更新
- 编码标准 — 命名、格式、注释规范
- 完成标准 — 明确的验收检查清单
文件四:STATUS.md — 状态外化

STATUS.md 是 Agent 的实时状态仪表板。它为人类(和下一个 session 的 Agent)提供全面的项目快照。
Session 恢复时,STATUS.md 是第一个被读取的文件。它必须包含以下九项信息:

| # | 内容 | 说明 |
|---|---|---|
| 1 | 项目简介 | 一段话说明项目是什么 |
| 2 | 里程碑状态表 | 每个里程碑的完成状态 |
| 3 | 本地设置命令 | 环境搭建一键命令 |
| 4 | 验证命令 | lint、test、build 命令 |
| 5 | 演示指南 | 如何运行和查看结果 |
| 6 | 数据模型概览 | 核心数据结构 |
| 7 | 模块实现摘要 | 每个模块干什么 |
| 8 | 仓库结构 | 目录树 |
| 9 | 故障排除 | 已知问题和解决方法 |
执行流程与 Agent Loop
执行流程总览
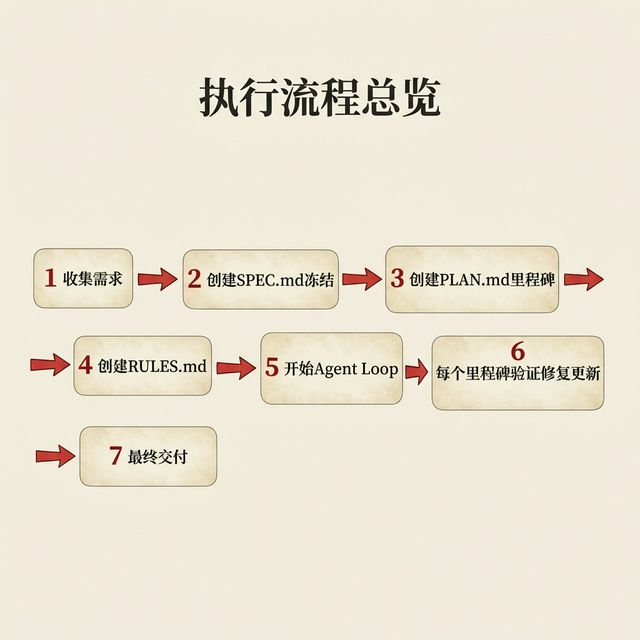
- 收集需求 — 用户描述项目目标、约束、交付物
- 创建 SPEC.md — Agent 草拟,人工审核后冻结
- 创建 PLAN.md — 制定里程碑序列 + 风险登记表 + 架构概述
- 创建 RULES.md — 设定行为约束和编码规范
- 开始 Agent Loop — 从第一个里程碑开始执行
- 每个里程碑:验证 → 修复 → 更新 — 确保每步都通过验证
- 最终验证 → 交付 — 全部里程碑完成后做最终扫描

Agent Loop — 七步循环
每个里程碑严格执行以下七步循环,直到所有里程碑完成:
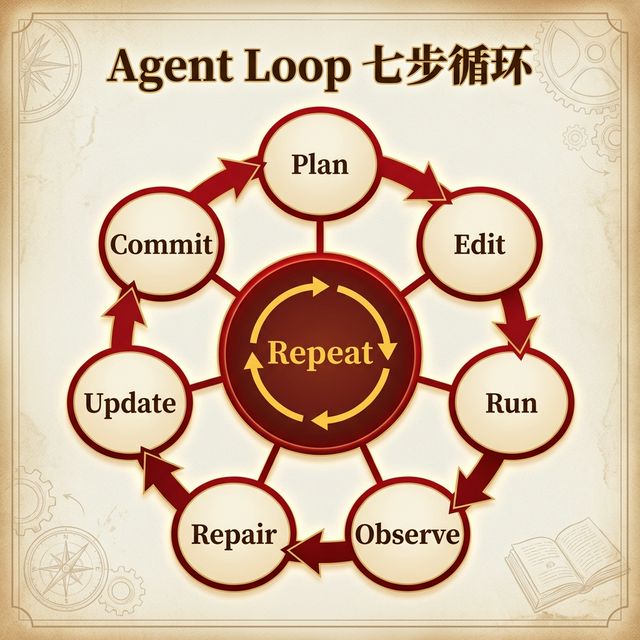

- Plan(规划) — 阅读当前里程碑的范围和验收标准,理解要做什么
- Edit(编码) — 编写代码,保持 diff 小且可审查
- Run(验证) — 执行验证命令:lint、typecheck、test、build
- Observe(观察) — 仔细阅读输出,理解每个错误和警告
- Repair(修复) — 立即修复所有失败,不留到下一个里程碑
- Update(更新) — 更新 STATUS.md 的状态表 + PLAN.md 的决策日志
- Commit(提交) — 清晰的 commit message,引用里程碑名称
Session 恢复机制

长任务的核心优势:四个文件不会因 session 中断而丢失。当 session 中断后,新 session 按以下顺序恢复:
- 读取
STATUS.md— 找到当前里程碑进度 - 读取
PLAN.md— 确认下一步做什么 - 读取
RULES.md— 恢复行为约束 - 读取
SPEC.md— 确认未偏离原始目标
七个设计模式
从 25 小时的实验中提炼出的七个核心设计模式,每个都解决长任务中的特定挑战:

① 不要停下来问
中断成本远大于小错误成本。遇到不确定的决定时,Agent 应自主决策并记录到决策日志,而不是中断工作流等待人工回复。宁可做错再修正,也不要停在那里等。
② 错误即测试
每个 bug 都是一个测试用例的诞生。遇到 bug 时,先写一个失败的测试来捕获这个问题,然后再修复代码让测试通过。这样确保同样的 bug 永远不会复发。

③ 目标/非目标对偶
明确写出「不做什么」和「做什么」一样重要。非目标是防止范围蔓延的防火墙。约束比扩展更重要 — 它让 Agent 不会在不相关的方向上浪费时间。
④ 确定性至上
所有结果必须可复现。避免随机种子、非确定性行为。做到一键启动、一键验证 — 任何人在任何时候运行同样的命令都应该得到同样的结果。

⑤ 里程碑粒度控制
每个里程碑应在单个循环内约 1 小时完成。太大则拆分,太小则合并。至少 14 个里程碑(原始实验用了 24 个)。粒度是控制力的关键。
⑥ 决策日志振荡抑制
记录每个重要决策的理由和替代方案。防止 Agent 在后续 session 中推翻之前的决定,导致代码来回修改。决策日志是系统的惯性飞轮。

⑦ 风险登记表前置
Fail Fast — 高风险先验证。在规划阶段识别技术风险(新 API、性能瓶颈、兼容性问题),将风险验证安排在最早的里程碑(M01-M03)。如果早期验证失败,立刻调整 PLAN,避免在错误的方向上走太远。
快速开始指南
新项目

- 告诉 Agent 使用 Long Horizon Tasks 方法论
- 提供项目需求:目标、约束、交付物、目标受众
- Agent 创建
SPEC.md,人工审核后冻结 - Agent 创建
PLAN.md,制定至少 14 个里程碑 - Agent 创建
RULES.md+STATUS.md - 开始 Agent Loop — 从 Milestone 01 自主执行至完成
进行中的项目

四文件系统可以在项目的任何阶段引入,不需要从零开始:
- 基于现有代码回填
SPEC.md,固定剩余目标 - 梳理剩余工作,创建
PLAN.md里程碑序列 - 设定
RULES.md行为约束 - 填写
STATUS.md记录当前进度
什么时候该用

✅ 适合使用
多里程碑复杂项目 · 预计耗时 5 小时以上 · 需要多次 Session 完成 · 从零构建完整应用 · 涉及多模块协作
❌ 不适合
简单 bug 修复 · 单文件小改动 · 一问一答操作 · 30 分钟内能完成的任务
实验数据与案例
原始实验数据

以下数据来自 OpenAI 的 Codex 25 小时自主编码实验 — 从零构建一个完整的在线协作设计工具:
| 指标 | 数据 |
|---|---|
| 总执行时间 | 25 小时 |
| Token 消耗量 | 13M tokens |
| 代码行数 | 30,000+ 行 |
| 里程碑数量 | 24 个 |
| 核心文件 | 4 个(SPEC + PLAN + RULES + STATUS) |
| Agent Loop 步骤 | 7 步循环 |
案例:design-desk

项目概况
协作设计工具 · React + TypeScript + WebSocket · 24 个里程碑 · 25 小时完成 · 30,000+ 行代码
关键成功因素
SPEC 提前冻结技术边界 · 风险登记表前置验证 WebSocket · 决策日志防止 SVG/Canvas 振荡 · STATUS.md 让中途恢复无缝
总结与行动建议
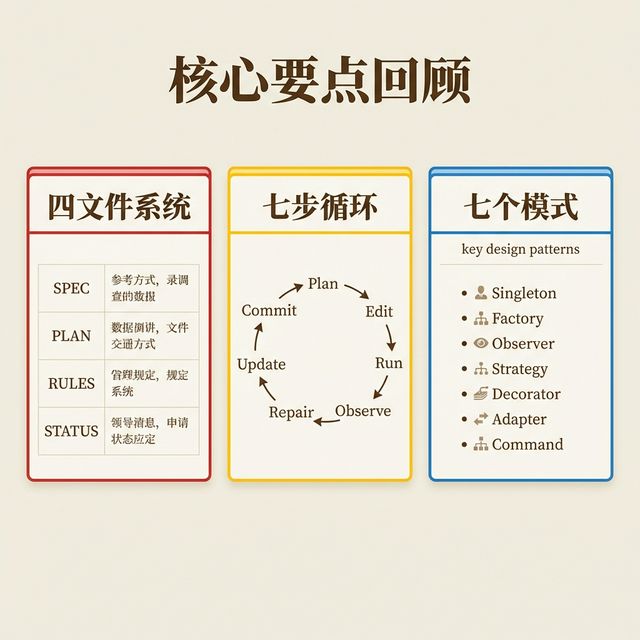
Long Horizon Tasks 方法论的核心非常简洁:
四文件系统
SPEC 锚定意图 · PLAN 指导执行 · RULES 约束行为 · STATUS 外化状态
七步循环
Plan · Edit · Run · Observe · Repair · Update · Commit
七个模式
不停下来问 · 错误即测试 · 确定性至上 · 风险前置
